This benchmark aims to advance robust reinforcement learning (RL) for real-world applications and domain adaptation. The benchmark provides a comprehensive set of tasks that cover various robustness requirements in the face of uncertainty on state, action, reward, and environmental dynamics, and spans diverse applications including control, robot manipulations, dexterous hand, and more. (This repository is under active development. We appreciate any constructive comments and suggestions).
🔥 Benchmark Features:
- High Modularity: It is designed for flexible adaptation to a variety of research needs, featuring high modularity to support a wide range of experiments.
- Task Coverage: It provides a comprehensive set of tasks to evaluate robustness across different RL scenarios.
- High Compatibility: It can be seamless and compatible with a wide range of existing environments.
- Support Vectorized Environments: It can enable parallel processing of multiple environments for efficient experimentation.
- Support for New Gym API: It fully supports the latest standards in Gym API, facilitating easy integration and expansion.
- LLMs Guide Robust Learning: Leverage LLMs to set robust parameters (LLMs as adversary policies).
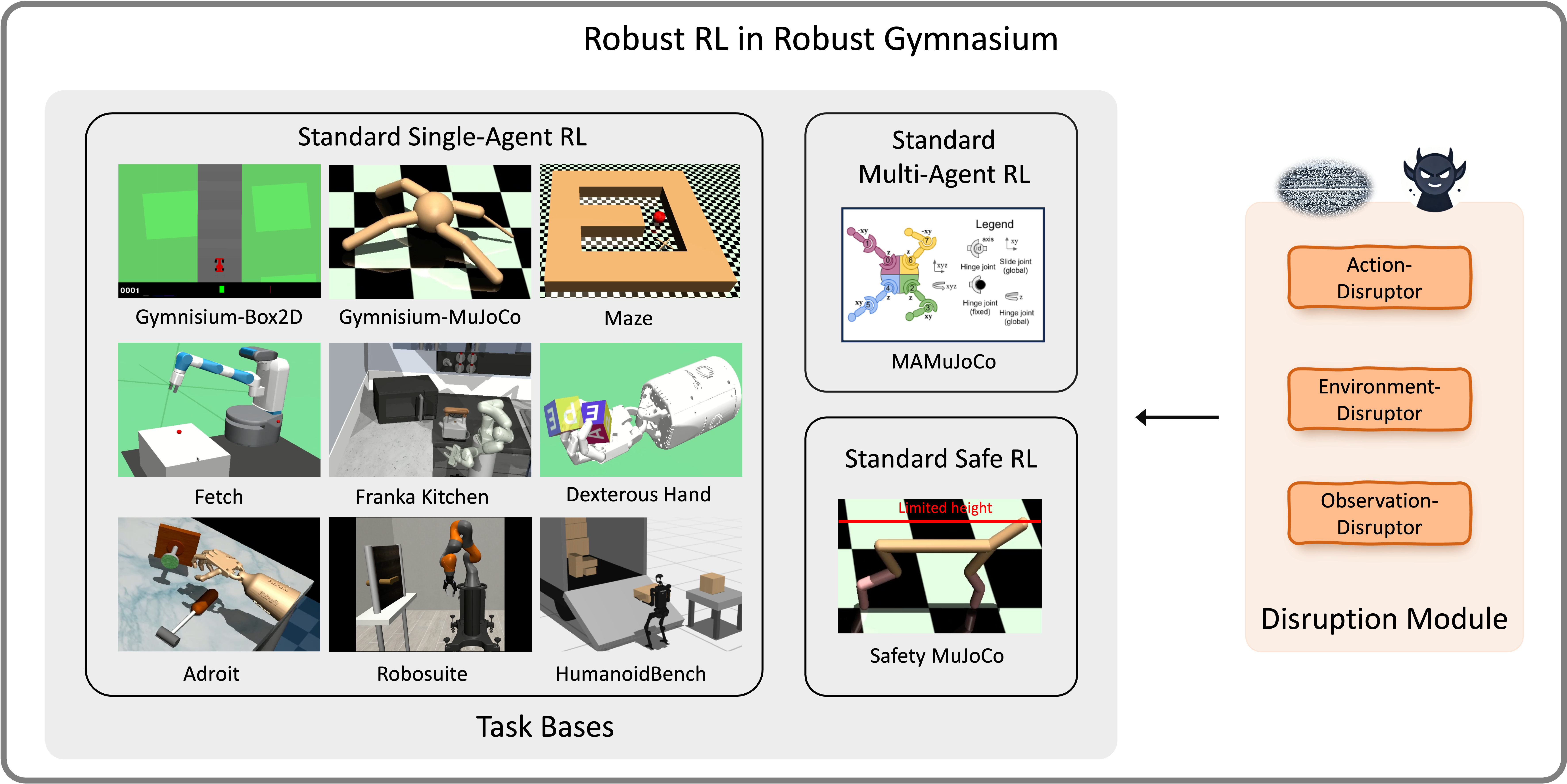
🔥 Benchmark Tasks:
- Robust MuJoCo Tasks: Tackle complex simulations with enhanced robustness.
- Robust Box2D Tasks: Engage with 2D physics environments designed for robustness evaluation.
- Robust Robot Manipulation Tasks: Robust robotic manipulation with Kuka and Franka robots.
- Robust Safety Tasks: Prioritize safety in robustness evaluation.
- Robust Android Hand Tasks: Explore sophisticated hand manipulation challenges in robust settings.
- Robust Dexterous Tasks: Advance the robust capabilities in dexterous robotics.
- Robust Fetch Manipulation Tasks: Robust object manipulation with Fetch robots.
- Robust Robot Kitchen Tasks: Robust manipulation in Kitchen environments with robots.
- Robust Maze Tasks: Robust navigation robots.
- Robust Multi-Agent Tasks: Facilitate robust coordination among multiple agents.
Each of these robust tasks incorporates elements such as robust observations, actions, reward signals, and dynamics to evaluate the robustness of RL algorithms.
🔥 Our Vision:
We hope this benchmark serves as a useful platform for pushing the boundaries of RL in real-world problems --- promoting robustness and domain adaptation ability!
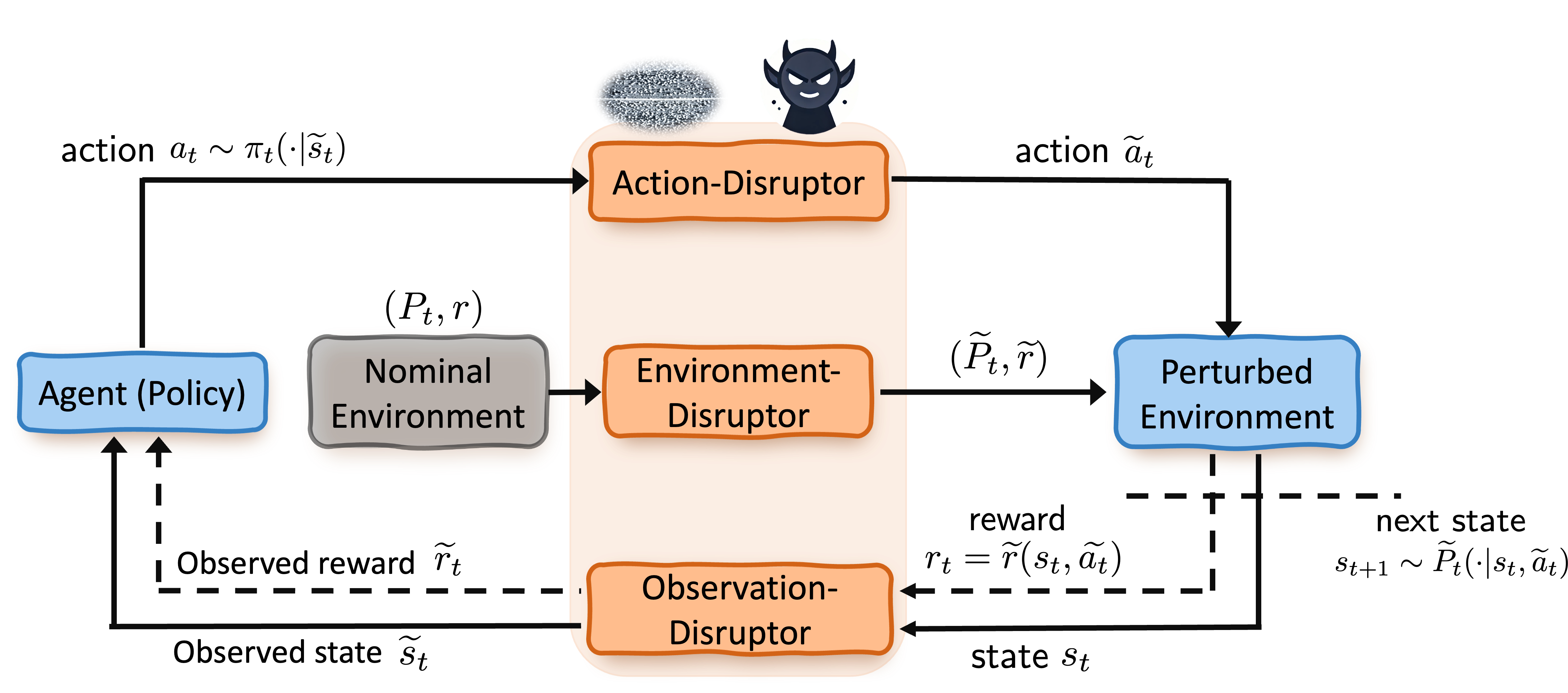
Robust RL problems typically consists of three modules:
- An agent (a policy): tries to learn a strategy π (a policy) based on the observation from the environment to achieve optimal long-term return
- An environment/task: a task that determines the agents' immediate reward r(·| s,a) and the physical or logical dynamics (transition function P(·| s,a))
- The disruptor module: represents the uncertainty/perturbation events that happen during any part of the interaction process between the agent and environment, with different modes, sources, and frequencies.
Opportunities for Future Research!
By leveraging this benchmark, we can evaluate the robustness of RL algorithms and develop new ones that perform reliably under real-world uncertainties and adversarial conditions. This involves creating agents that maintain their performance despite distributional shifts, noisy data, and unforeseen perturbations. Therefore, there are vast opportunities for future research with this benchmark, such as:
- Integrating techniques from robust optimization, adversarial training, LLMs, and safe learning to enhance generalization and adaptability.
- Improving sample efficiency and safety in robust settings, which is crucial for deploying these systems in high-stakes applications like healthcare, finance, and autonomous vehicles.
In conclusion, by using this benchmark, we can test and refine the robustness of RL algorithms before deploying them in diverse, real-world scenarios.